
Research models for creating storyboards using AI technology.
2024-02-19 04:57:03
Recently a research report was published comparing AI models in visualization for storyboarding. Movie scenes and animation By benchmarking Pipeline 1 in Stable Diffusion 1.5 mode, using DreamBooth and the LoRA model to promote a specific character AI with specific training and combining it with text inversion to train a specific style, and Pipeline 2 combines cross-attention control to create time-consistent images of Pipeline's latest Stable Diffusion XL release (July 18, 23 ).
How it works in the visualization of each structure
1.Use Diffusion Models
It is a simulation model used to create images. These models stand out due to their ability to generate high-quality samples and perform tasks such as image synthesis and noise reduction. One prominent diffusion model is the Variational Diffusion Autoencoder (VDAE), which combines the principles of Variational Autoencoder (VAE) with a diffusion process to provide improved generative modeling.
2.Stable Diffusion
As a structure, diffusion models play an important role in synthesizing high-quality samples from complex data distributions. However, traditional diffusion models may encounter stability-related problems in the construction process. A stable diffusion model (SDM) has been introduced to combine stability mechanisms to increase convergence and robustness.
3.Stable Diffusion XL
Stable Diffusion XL (SDXL) is a major advance in imaging. Building on the success of its predecessor Stable Diffusion, it uses a larger U-Net model with 2.6 billion parameters. This allows for finer details and more complex images. SDXL uses a different distribution of Transformer blocks. It optimizes the learning process and promotes improved image fidelity
4.DreamBooth
DreamBooth works by changing the structure of the model itself. We have two inputs to consider. The first input is the image we want to train. and the second input is a sentence that has a unique identifier. byDreamBooth Train the model to associate unique identifiers with the image concepts to be trained. Sentences are converted to text embeddings. each word is represented by a vector containing semantic information about the word. The vector contains information about each word, and concepts (images) are associated with a new vector of words without meaning. The DreamBooth model is based on the conditional Generative Adversarial Network (GCN) architecture.
5. TextualInversion.
Similar to DreamBooth, gradient updates do not occur in the model, but in the vector. The vector will gradually approach the desired visual phenomenon and ultimately obtain the vector. This can almost perfectly describe the desired image. The advantage of text reversal is the output, rather than a new model like DreamBooth. Except for its additional embedding, it stores data more efficiently than DreamBooth and anyone else. Easily download, embed, and insert models, and obtain the desired image output.
6. LorA
Lora represents low-rank adaptation in DreamBooth. It is an auxiliary model similar to Lora's text reversal. Add new weights and update them to achieve the same results. Lora’s training is faster than DreamBooth. And it uses much less memory. In addition, due to the tiny size of the LorA layer,
Examples of DreamBoth, Text Inversion, Lora, and Hypernetworks models
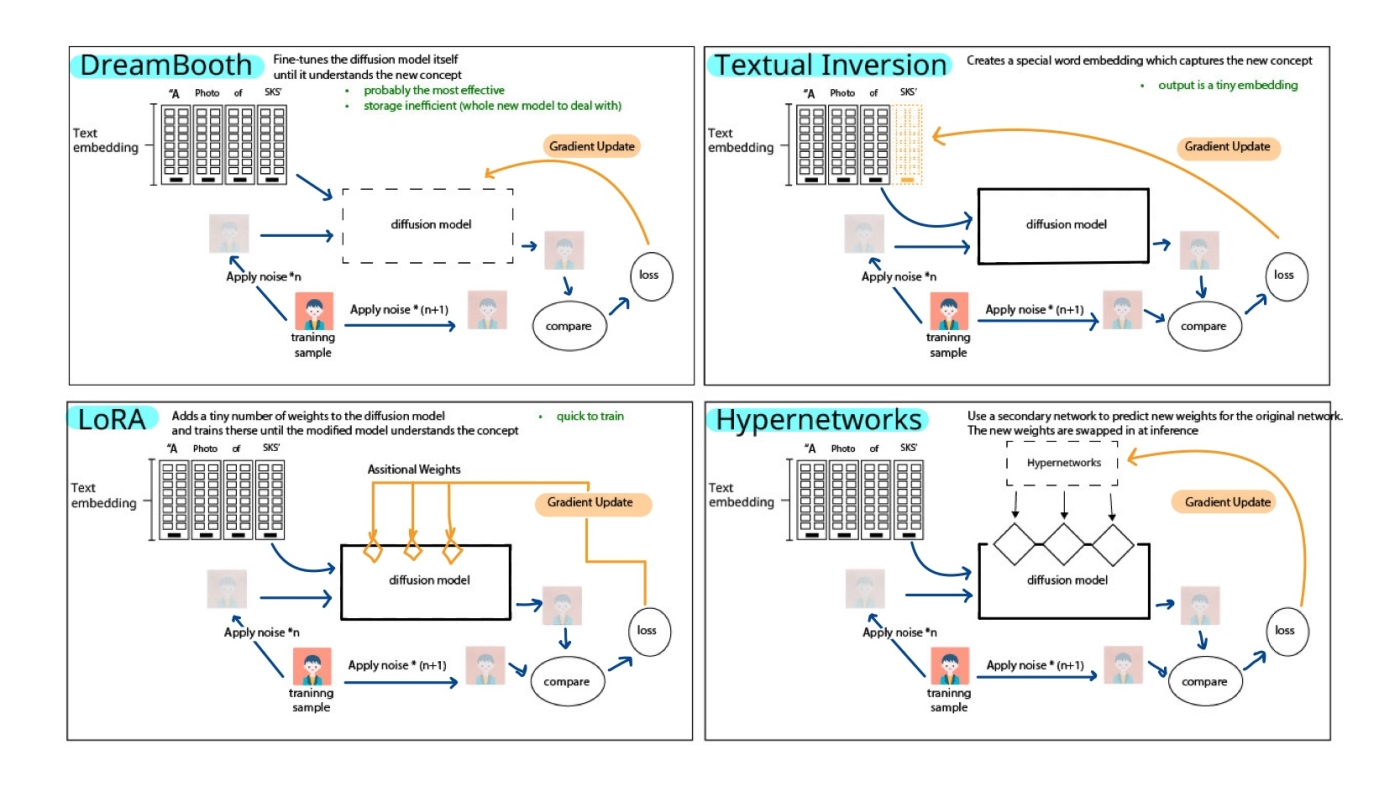
The research has developed and trained AI models to be able to create images that match the prompts in various problems covering the use of Stable Diffusion models and text inversion. to create consistent images for various creative applications Including storyboards Animated movie scenes and children's stories This project makes use of advanced techniques such as DreamBooth and specialized character training. It offers detailed insights into training scripts. Inference code and the results obtained This project exemplifies the potential of integrating AI models and complex methodologies to create engaging and consistent imagery for a variety of storytelling purposes. It emphasizes the importance of AI advancements in visual content creation.
Leave a comment :
Recent post

2025-01-10 10:12:01


2024-05-31 03:06:49

2024-05-28 03:09:25
Tagscloud
Other interesting articles
There are many other interesting articles, try selecting them from below.

2024-09-04 01:12:36
2023-10-18 04:37:58

2024-04-09 04:26:05

2025-03-26 10:38:23


2024-09-17 02:19:52

2025-04-17 10:32:59

2025-04-18 03:18:46

2024-09-04 01:03:32