
วิจัยโมเดลสร้างสตอรี่บอร์ดด้วยเทคโนโลยี AI
2024-02-19 04:57:03
เมื่อไม่นานมานี้ได้มีการเผยแพร่รายงานการวิจัยเปรียบเทียบโมเดล AI ในการสร้างภาพสำหรับการสร้างสตอรี่บอร์ด ฉากภาพยตร์และแอนิเมชัน โดยการใช้การเปรียบเทียบประสิทธิภาพ Pipeline 1 ในโหมด Stable Diffusion 1.5 โดยใช้งาน DreamBooth และแบบจำลอง LoRA ในการPromp AI ของตัวละครที่เฉพาะที่มีการฝึกที่เจาะจงและรวมเข้ากับการกลับข้อความเพื่อฝึกสไตล์ที่เฉพาะเจาะจง และ Pipeline 2 รวมการควบคุมความสนใจข้ามเพื่อสร้างภาพที่สอดคล้องกันตามเวลาของ Pipeline ล่าสุด Stable Diffusion XL ที่ออกใหม่ (18 กรกฎาคม 23 )
วิธีการทำงานในการสร้างภาพของแต่ละโครงสร้าง
1.ใช้ Diffusion Models
เป็นโมเดลจำลองที่ใช้ในการสร้างภาพ ซึ่งโมเดลเหล่านี้มีความโดดเด่นเนื่องจากความสามารถในการสร้างตัวอย่างคุณภาพสูงและดำเนินการต่างๆ เช่น การสังเคราะห์ภาพและการลดสัญญาณรบกวน รูปแบบการแพร่กระจายที่โดดเด่นอย่างหนึ่งคือ Variational Diffusion Autoencoder (VDAE) ซึ่งรวมหลักการของ Variational Autoencoder (VAE) เข้ากับกระบวนการแพร่กระจายเพื่อปรับปรุงการสร้างแบบจำลองกำเนิดที่ได้รับการปรับปรุง
2.Stable Diffusion
เป็นโครงสร้างโมเดลการแพร่กระจายมีบทบาทสำคัญในการสังเคราะห์ตัวอย่างที่มีคุณภาพสูงจากการกระจายข้อมูลที่ซับซ้อน อย่างไรก็ตาม รูปแบบการแพร่กระจายแบบดั้งเดิมอาจพบปัญหาที่เกี่ยวข้องกับความมั่นคงในกระบวนการสร้าง รูปแบบการแพร่กระจายที่มีเสถียรภาพ (SDM) ได้รับการแนะนำเป็นทางออกที่รวมกลไกความเสถียรเพื่อเพิ่มการบรรจบกันและความทนทาน
3.Stable Diffusion XL
Stable Diffusion XL (SDXL) เป็นความก้าวหน้าครั้งสำคัญในการสร้างภาพ โดยต่อยอดมาจากความสำเร็จของ Stable Diffusion รุ่นก่อน ใช้โมเดล U-Net ที่ใหญ่กว่าพร้อมพารามิเตอร์ 2.6 พันล้านพารามิเตอร์ ช่วยให้เก็บรายละเอียดได้ละเอียดยิ่งขึ้นและภาพที่ซับซ้อนยิ่งขึ้น SDXL ใช้การกระจายบล็อก Transformer ที่แตกต่างกัน เพิ่มประสิทธิภาพกระบวนการเรียนรู้และส่งเสริมความเที่ยงตรงของภาพที่ได้รับการปรับปรุง
4.DreamBooth
DreamBooth ทำงานโดยการเปลี่ยนโครงสร้างของตัวโมเดลเอง เรามีอินพุต 2 อินพุตที่เราต้องคำนึงถึง อินพุตแรกคือรูปภาพที่เราต้องการฝึก และอินพุตที่สองคือประโยคซึ่งมีตัวระบุที่ไม่ซ้ำกัน โดยDreamBooth ฝึกโมเดลเพื่อเชื่อมโยงตัวระบุที่ไม่ซ้ำกับแนวคิดของรูปภาพที่จะฝึก ประโยคจะถูกแปลงเป็นการฝังข้อความ โดยที่แต่ละคำจะแสดงด้วยเวกเตอร์ที่มีข้อมูลความหมายเกี่ยวกับคำนั้น และเวกเตอร์ประกอบด้วยข้อมูลเกี่ยวกับแต่ละคำ และแนวคิด (รูปภาพ) เชื่อมโยงกับเวกเตอร์ใหม่ของคำที่ไม่มีความหมายใดๆ โมเดล DreamBooth ขึ้นอยู่กับสถาปัตยกรรม Generative Adversarial Network (cGAN) แบบมีเงื่อนไข
5.Textual Inversion
คล้ายกับ DreamBooth ความแตกต่างก็คือการอัปเดตการไล่ระดับสีจะไม่เกิดขึ้นในโมเดล แต่จะเกิดขึ้นในเวกเตอร์ และเวกเตอร์จะเข้าใกล้ปรากฏการณ์ทางสายตาที่ต้องการอย่างช้าๆ และในที่สุด เราก็จะได้เวกเตอร์ ซึ่งเกือบจะสามารถอธิบายภาพที่ต้องการได้อย่างสมบูรณ์แบบ ข้อดีของการกลับข้อความคือเอาต์พุตไม่ใช่โมเดลใหม่เช่น DreamBooth ยกเว้นว่าเป็นการฝังเพิ่มเติมเล็กน้อย ดังนั้นจึงมีประสิทธิภาพในการจัดเก็บข้อมูลมากกว่า DreamBooth มากและใครๆ ก็สามารถดาวน์โหลดการฝังและเสียบเข้ากับโมเดลของตนได้อย่างง่ายดาย และยังได้เอาต์พุตภาพที่ต้องการอีกด้วย
6.LoRA
LoRA ย่อมาจาก Low-Rank Adaption ใน DreamBooth คือโมเดลเสริมเหมือนกับ Textual Inversion โดยLoRA เพิ่มน้ำหนักใหม่และอัปเดตน้ำหนักใหม่เหล่านั้นเพื่อให้ได้ผลลัพธ์ที่เหมือนกันทุกประการ การฝึกอบรม LoRA เร็วกว่า DreamBooth มาก และใช้หน่วยความจำน้อยกว่ามาก นอกจากนี้ เนื่องจากเลเยอร์ LoRA มีขนาดเล็กมาก
ตัวอย่างแบบจำลอง DreamBoth, Textual Inversion, LoRA และ Hypernetworks
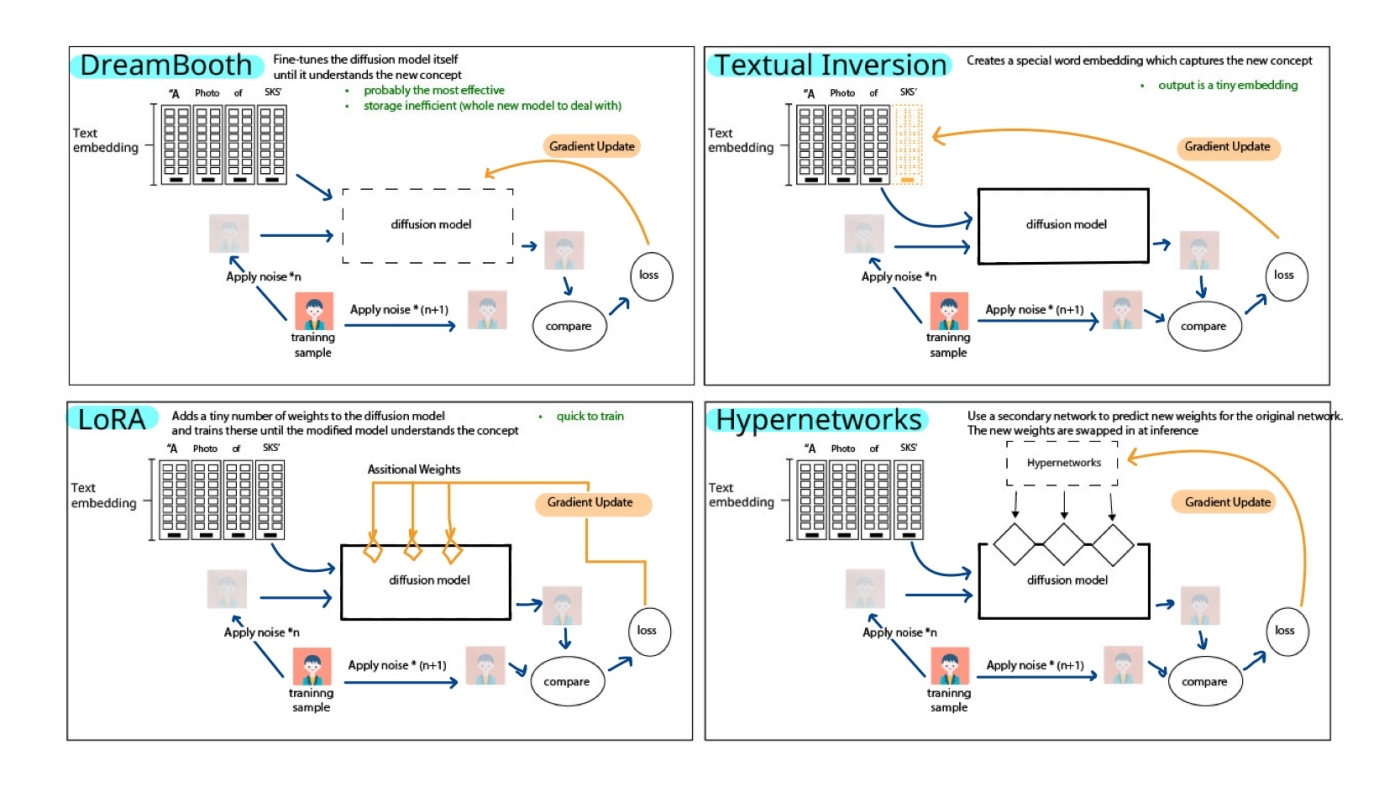
อ้างอิงจากรายงานการสร้างภาพด้วย AI
โดยวิจัยมีการพัฒนาและฝึกสอนโมเดล AI ให้สามารถสร้างภาพได้ตรงกับการ promp ในโจทย์ต่าง ๆ ที่ครอบคลุมเกี่ยวกับการใช้แบบจำลอง Stable Diffusion และการผกผันของข้อความ เพื่อสร้างภาพที่สม่ำเสมอสำหรับการใช้งานเชิงสร้างสรรค์ต่างๆ รวมถึงสตอรี่บอร์ด ฉากภาพยนตร์แอนิเมชัน และเรื่องราวของเด็ก โปรเจกต์นี้ใช้ประโยชน์จากเทคนิคขั้นสูง เช่น DreamBooth และการฝึกตัวละครโดยเฉพาะ โดยนำเสนอข้อมูลเชิงลึกโดยละเอียดเกี่ยวกับสคริปต์การฝึก รหัสการอนุมาน และผลลัพธ์ที่ได้ โครงการนี้เป็นตัวอย่างศักยภาพของการบูรณาการโมเดล AI และวิธีการที่ซับซ้อนเพื่อสร้างภาพที่น่าดึงดูดและสอดคล้องกันเพื่อวัตถุประสงค์ในการเล่าเรื่องที่หลากหลาย โดยเน้นย้ำถึงความสำคัญของความก้าวหน้าของ AI ในการสร้างเนื้อหาภาพ
ร่วมเเสดงความคิดเห็น :
Recent post

2025-01-10 10:12:01

2024-06-10 03:19:31

2024-05-31 03:06:49

2024-05-28 03:09:25
Tagscloud
บทความอื่นๆที่น่าสนใจ
บทความที่น่าสนใจอื่นๆยังมีอีกมากลองเลืือกดูจากด้านล่างนี้ได้นะครับ

2024-08-13 02:24:11

2025-05-06 09:34:54

2024-12-17 04:04:33

2024-01-19 05:45:32

2023-11-01 02:54:29

2023-11-10 10:29:12

2024-10-10 11:35:58

2025-02-19 10:22:00

2025-03-31 03:30:20