
บทนำเกี่ยวกับข้อมูลราคาของ Stooq
2025-05-28 09:01:33
ในบทความก่อนหน้าเราได้เรียนรู้วิธีการตั้งค่าสภาพแวดล้อมสำหรับการสร้างต้นแบบการซื้อขายอัลกอริธึมโดยใช้ Jupyter Notebooks เราใช้ข้อมูลจาก Yahoo กับ Pandas DataReader ในบทความนี้เราจะมาดูผู้ให้บริการข้อมูลตลาดฟรีอีกหนึ่งรายคือ Stooq
หากคุณต้องการติดตามบทแนะนำและยังไม่ได้ตั้งค่าสภาพแวดล้อมการสร้างต้นแบบ คุณจะต้อง:
- Jupyter v1.0
- Pandas v1.4
- Pandas-DataReader v0.10
- ข้อมูลประจำวันย้อนหลังจากภูมิภาคสหรัฐอเมริกาที่จัดทำโดย Stooq
Stooq เป็นเว็บไซต์โปแลนด์ที่ได้รับการแปลเป็นภาษาอังกฤษบางส่วนแล้ว ณ เวลาที่เขียน Stooq มีข้อมูล OHLCV สำหรับหลักทรัพย์และ ETF ทั่วโลก 21,332 รายการ คู่สกุลเงิน 1,980 คู่ และสกุลเงินดิจิทัล 132 รายการ พวกเขายังมีข้อมูลเกี่ยวกับดัชนีทั่วโลก สินค้าโภคภัณฑ์ และพันธบัตรด้วย เช่นเดียวกับ Yahoo ข้อมูลทั้งหมดที่มีให้บริการสามารถเข้าถึงได้ผ่านทางเว็บอินเตอร์เฟซ และข้อมูล OHLCV สามารถดาวน์โหลดในรูปแบบ CSV ได้ ไม่มี API สำหรับ Stooq สำหรับหุ้นที่จดทะเบียนในตลาดหลักทรัพย์ของสหรัฐอเมริกา ยังสามารถรับข้อมูลพื้นฐานบางอย่าง เช่น อัตราส่วนราคาต่อกำไร และมูลค่าตลาดได้ แม้ว่าจะไม่มีการดาวน์โหลดข้อมูลประวัติศาสตร์สำหรับข้อมูลเหล่านี้ก็ตาม คุณสามารถค้นหาตัวย่อหุ้นและดาวน์โหลดข้อมูลปัจจุบันทั้งหมดที่เกี่ยวข้องกับมันผ่านหน้าสัญลักษณ์ หรือคุณสามารถเข้าถึงข้อมูลปัจจุบันและข้อมูลประวัติที่นี่
หมายเหตุเกี่ยวกับการตั้งชื่อสัญลักษณ์หุ้น
คุณสามารถค้นหาหรือยืนยันสัญลักษณ์หุ้นได้โดยใช้แถบค้นหาที่มีอยู่ที่ด้านบนของหน้า นี่คือการเปลี่ยนแปลงในชื่อเรียกที่พบบ่อยที่สุดบางส่วน:
- ดัชนีจะมีเครื่องหมาย ^ นำหน้า เช่น ^DJI (Dow Jones Industrial), ^UK100 (FTSE100)
- หุ้นสหรัฐอเมริกาจะมีการเติมท้ายด้วย .US เช่น AAPL.US, MSFT.US, TSLA.US
- สกุลเงินดิจิทัลจะมีการเติมต่อท้ายด้วย .V เช่น BTC.V (BitCoin)
- หุ้นของสหราชอาณาจักรจะมีคำต่อท้ายเป็น .UK เช่น AV.UK (Aviva)
- ราคาต่อกำไรจะมีการเติมท้ายด้วย _PE.US เช่น AAPL_PE.US
ข้อมูลประวัติศาสตร์ของ Stooq
Stooq มีข้อมูลประวัติรายวัน รายชั่วโมง และรายนาทีเกี่ยวกับดัชนี ETF หุ้น พันธบัตร ฟอเร็กซ์ และสกุลเงินดิจิทัล เพื่อให้ได้ข้อมูล คุณต้องดาวน์โหลดตามภูมิภาคและจากนั้นตามความถี่ ETF และหุ้นจะถูกดาวน์โหลดตามภูมิภาคที่เฉพาะเจาะจง ในขณะที่ข้อมูลของสกุลเงินดิจิทัล ฟอเร็กซ์ ดัชนี และพันธบัตรจะมีให้ในภูมิภาคที่ชื่อว่าโลก เมื่อคุณเลือกชุดข้อมูลที่ต้องการโดยคลิกที่ลิงก์ในคอลัมน์ ASCII คุณจะต้องกรอก CAPTCHA และยืนยันการดาวน์โหลดของคุณ คุณจะได้รับไฟล์ zip ที่มีข้อมูลสำหรับความถี่เวลาที่คุณเลือก สำหรับบทแนะนำนี้ เราจะใช้ข้อมูลรายวันจากภูมิภาคสหรัฐอเมริกา
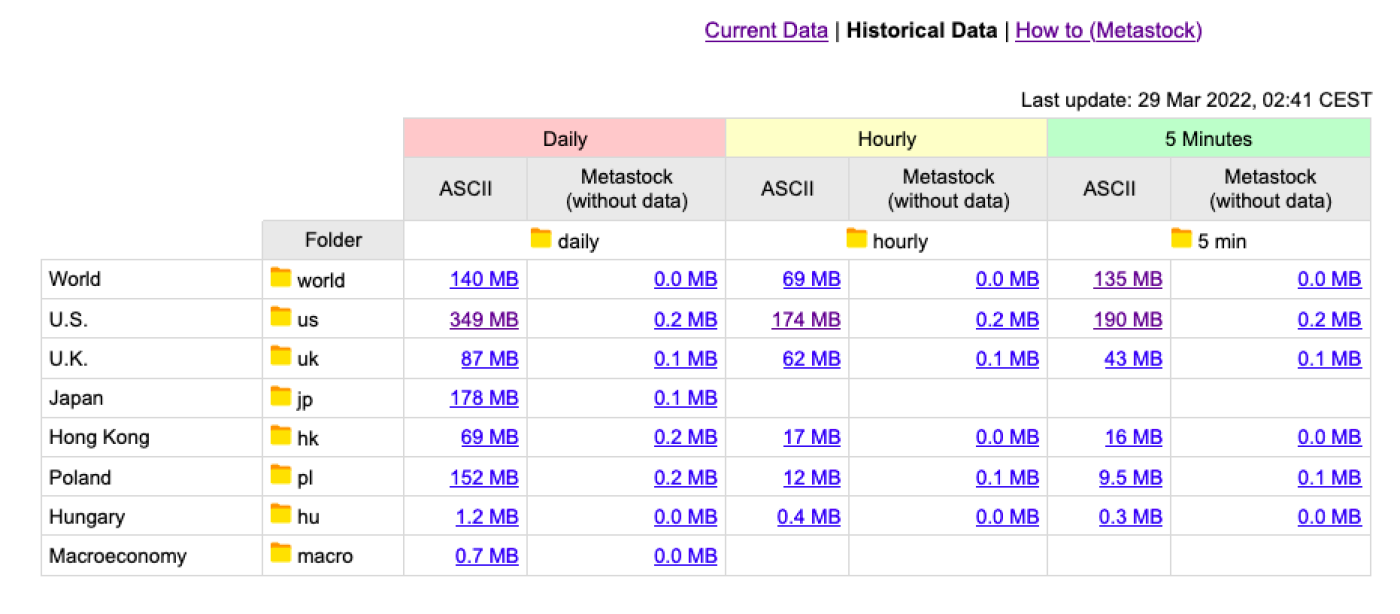
เมื่อแตกไฟล์ ขนาดไฟล์จะขึ้นอยู่กับภูมิภาคและความถี่ของคุณ ข้อมูลประวัติรายวันสำหรับหุ้นบางตัวในสหรัฐอเมริกาสามารถย้อนกลับไปได้มากกว่า 30 ปี และไฟล์ที่แตกออกมาใช้พื้นที่มากกว่า 1.4GB ดังนั้นโปรดตรวจสอบให้แน่ใจว่ามีพื้นที่เก็บข้อมูลเพียงพอ ข้อมูลรายชั่วโมงให้ข้อมูลล่าสุดถึง 1,400 จุดข้อมูล ซึ่งเท่ากับประมาณ 9 เดือน ขึ้นอยู่กับความปลอดภัย ในขณะที่ข้อมูลทุก 5 นาทีให้ข้อมูลล่าสุดถึง 2,000 จุดข้อมูลสำหรับความปลอดภัย และเท่ากับประมาณ 1 เดือน
Stooq แบ่งข้อมูลจากแต่ละภูมิภาคไปยังระดับตลาดหลักทรัพย์ จากนั้นจึงแบ่งหุ้นและ ETFs สำหรับตลาดหลักทรัพย์ที่มีปริมาณหุ้นสูง ไฟล์จะถูกแบ่งย่อยเพิ่มเติมเพื่อให้มีหุ้นสูงสุด 2000 หุ้นต่อไดเรกทอรี สิ่งนี้ทำให้การเข้าถึงข้อมูลยากขึ้น อย่างไรก็ตาม เว็บไซต์ Stooq มีข้อมูลเกี่ยวกับโครงสร้างไดเรกทอรีที่แนะนำสำหรับการดาวน์โหลดตามที่แสดงในรูปด้านล่าง

การใช้สภาพแวดล้อมการสร้างต้นแบบที่เราตั้งค่าด้วย Jupyter notebooks ในบทความก่อนหน้านี้ เราจะดูวิธีการดึงข้อมูลจากหุ้นเดียวและจากรายการหุ้น ในการติดตามบทแนะนำนี้ คุณจะต้องมี Jupyter notebooks ที่รัน Python 3.6 หรือสูงกว่า เราจะใช้ Pandas และ Pandas DataReader
การเข้าถึงหุ้นเดียว
เมื่อคุณดาวน์โหลดและแตกไฟล์จาก Stooq เสร็จแล้ว คุณจะต้องเปิด Jupyter notebook ตามที่ได้กล่าวไว้ในบทความก่อนหน้านี้ คุณจะต้องทำสิ่งนี้จากสภาพแวดล้อมพื้นฐานของ Anaconda ของคุณ เราได้ติดตั้งและกำหนดค่า Ipykernel ไว้ก่อนหน้านี้แล้ว ดังนั้นคุณจะสามารถเข้าถึงเคอร์เนลที่ถูกต้องสำหรับสภาพแวดล้อมเสมือนของคุณได้โดยตรงผ่าน Jupyter สร้างสมุดบันทึกใหม่และเลือกเคอร์เนลที่ต้องการ หากคุณติดตามบทความในซีรีส์นี้ เคอร์เนลนี้จะเรียกว่า py3.8
เราจะเริ่มต้นด้วยการเพิ่มการนำเข้า ก่อนอื่นที่เราต้องนำเข้าคือ Pandas
import pandas as pdในตอนนี้เป็นความคิดที่ดีที่จะทำความคุ้นเคยกับตำแหน่งของข้อมูลที่คุณดาวน์โหลดมา คุณจะต้องป้อนเส้นทางไปยังไดเรกทอรีใน Pandas ฟังก์ชัน read_csv() ของ Pandas เป็นฟังก์ชันที่มีความยืดหยุ่นอย่างมาก มันช่วยให้คุณสามารถอ่านไฟล์ .csv และ .txt โดยตรงเข้าสู่ DataFrame เพื่อการวิเคราะห์ต่อไปได้ คุณสามารถกำหนดโครงสร้างของ DataFrame ของคุณได้มากมายภายในฟังก์ชันนี้ คุณสามารถเลือกแถวสำหรับหัวคอลัมน์และคอลัมน์ที่จะใช้เป็นดัชนีได้ คุณสามารถข้ามแถวหรือส่วนท้ายของไฟล์ จำกัดจำนวนแถวที่อ่านได้ และยังสามารถอนุมานวันที่และเวลาได้อีกด้วย ยังมีตัวเลือกในการส่งพจนานุกรมของชื่อคอลัมน์พร้อมค่าที่เป็นฟังก์ชันที่จะนำไปใช้กับคอลัมน์ด้วย ข้อมูลเพิ่มเติมสามารถดูได้ที่นี่
เริ่มต้นเราจะอ่านข้อมูลลงใน DataFrame และทำการประมวลผลหลังจากนั้น ในกรณีนี้เราจะดูข้อมูลที่ให้มาสำหรับ AAPL ไฟล์นี้ควรอยู่ภายใต้เส้นทาง .../data/daily/us/nasdaq stocks/1/aapl.us.txt เมื่อคุณพบไฟล์แล้ว สิ่งที่คุณต้องทำคือส่งไปยัง read_csv() การเรียกใช้เมธอด head() ของ Pandas จะช่วยให้คุณสามารถดู DataFrame ได้
stooq_aapl = pd.read_csv("path/to/your/download/data/daily/us/nasdaq stocks/1/aapl.us.txt")
stooq_aapl.head()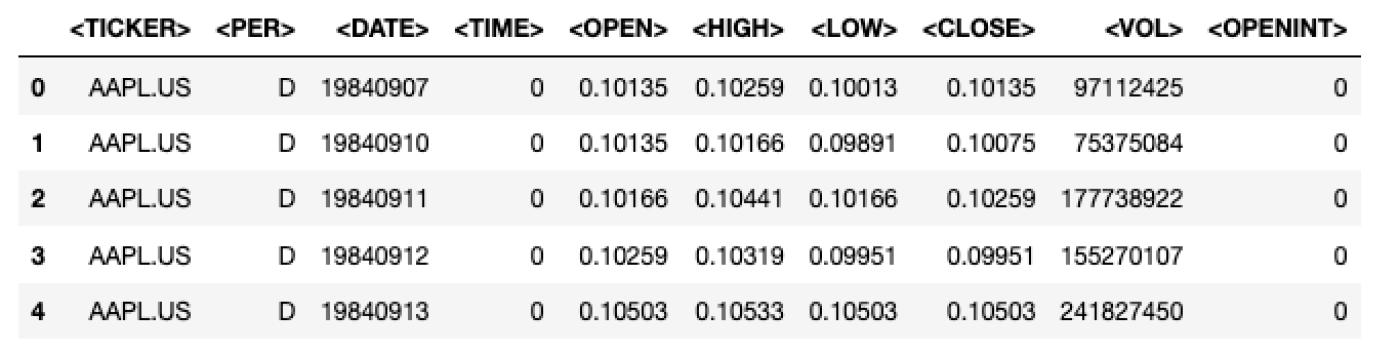
ตอนนี้เรามีข้อมูล OHLCV ของเราในรูปแบบ DataFrame แต่เราต้องทำงานบางอย่างเพื่อให้มันอยู่ในสภาพที่ใช้งานได้ ถ้าเราเรียก stooq_aapl.dtypes เราจะเห็นประเภทข้อมูลของแต่ละคอลัมน์ คุณจะสังเกตเห็นว่า วันที่ของเราเก็บเป็นจำนวนเต็ม เพื่อให้เราสามารถทำการวิเคราะห์อนุกรมเวลาได้ ข้อมูลนี้ควรแปลงเป็นวัตถุวันที่และเวลา ในการแปลง เราสามารถใช้ pd.to_datetime() ได้ อย่างไรก็ตาม วิธีนี้ต้องใช้สตริงเป็นข้อมูลนำเข้า ดังนั้นเราจึงต้องแปลงจำนวนเต็มเป็นสตริงก่อนโดยใช้วิธี astype() เราสามารถใช้การจัดรูปแบบ strftime เพื่อสร้างวัตถุ datetime ได้ ตอนนี้เราสามารถใช้คอลัมน์วันที่เป็นดัชนีของเราได้ เรายังมีคอลัมน์บางส่วนที่เราไม่ต้องการและชื่อคอลัมน์หรือหัวข้อคอลัมน์สามารถอ่านได้ง่ายขึ้น โค้ดต่อไปนี้จะทำการเปลี่ยนแปลงที่จำเป็น
# First we drop the unwanted columns
stooq_aapl = stooq_aapl.drop(['', '', '', ''], axis=1)
# We relabel the column headers
stooq_aapl.columns = ["date","open", "high", "low", "close", "volume"]
# convert the date integer to a datetime object
stooq_aapl["date"] = pd.to_datetime(stooq_aapl['date'].astype(str), format = '%Y%m%d')
# set the date column as the index
stooq_aapl = stooq_aapl.set_index('date')DataFrame สุดท้ายของเรามีลักษณะดังนี้และพร้อมสำหรับการวิเคราะห์เพิ่มเติม
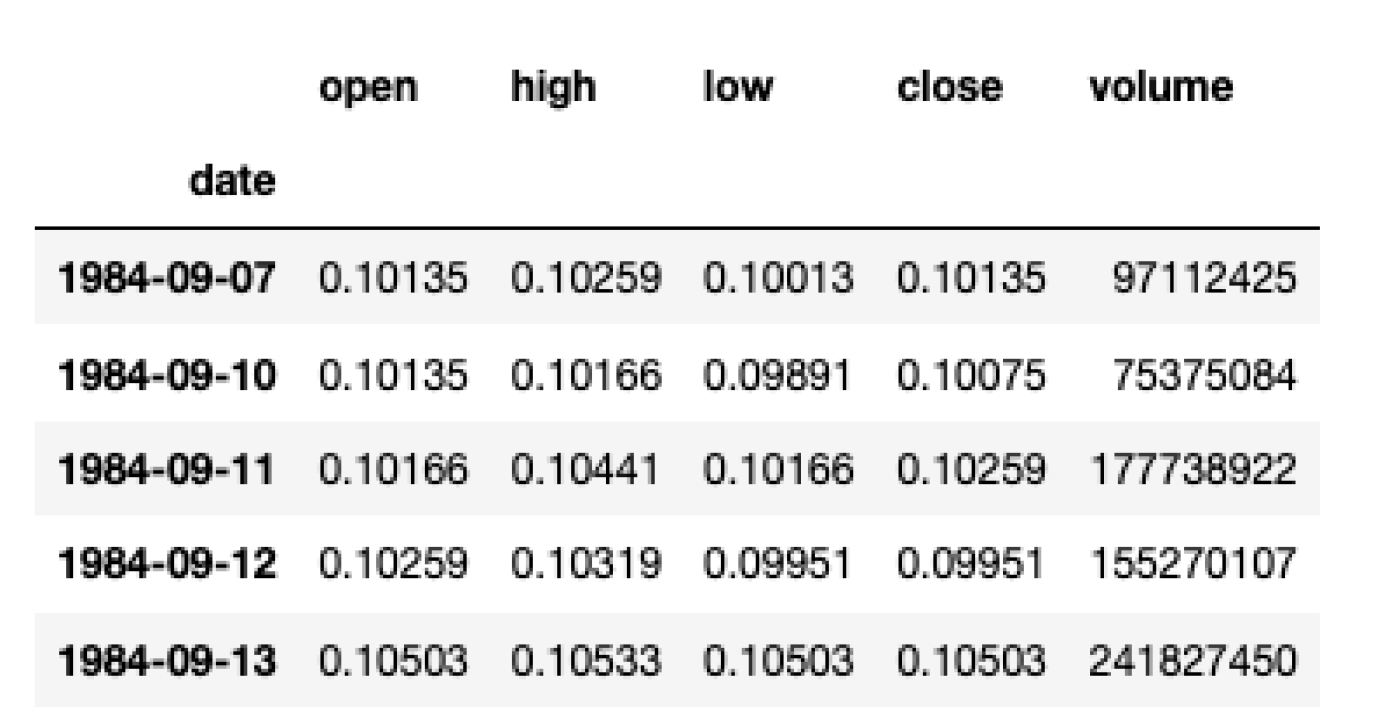
หมายเหตุเกี่ยวกับราคาปิด
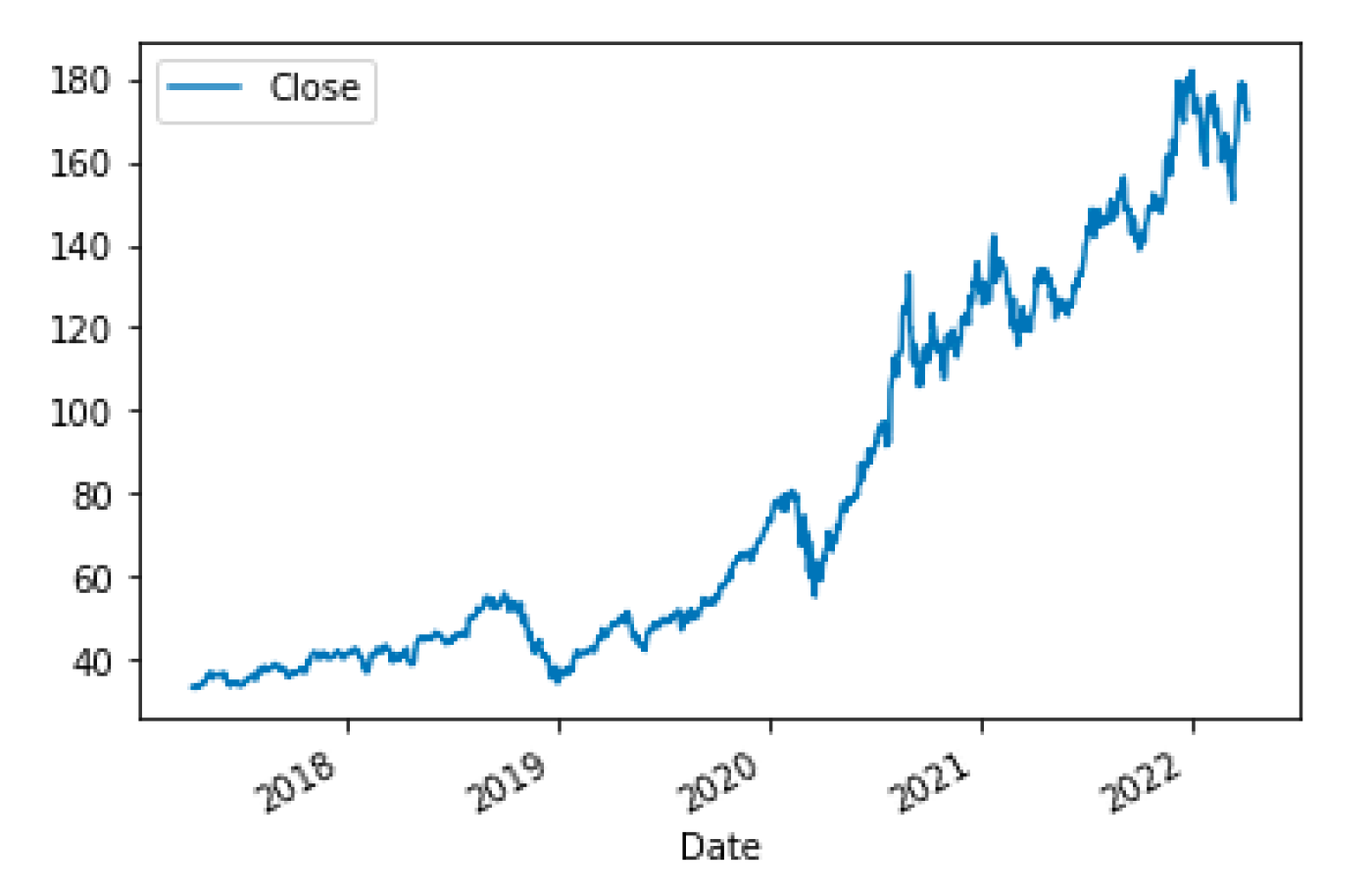
ควรสังเกตว่าราคาปิดที่ Stooq ให้ไว้นั้นเป็นราคาปิดที่ปรับแล้วจริงๆ สิ่งนี้สามารถเห็นได้จากการวาดกราฟราคาปิดในช่วงเวลาที่รวมถึงการแบ่งหุ้น ในกรณีของ Apple มีการแบ่งหุ้นแบบ 4 ต่อ 1 เมื่อวันที่ 28 สิงหาคม 2020 เมื่อเกิดเหตุการณ์นี้ ราคาปิดสามารถเห็นได้ว่าลดลงอย่างมากในชั่วข้ามคืน ทำให้เกิดเส้นตรงเกือบตั้งฉากบนกราฟเวลา
stooq_aapl.plot(y="close")
ในภาพด้านล่างคุณสามารถเห็นได้ว่าไม่มีการลดลงอย่างมากในช่วงเวลานี้ สิ่งนี้บ่งชี้ว่าราคาปิดได้ถูกปรับแล้วจริงๆ หนึ่งในปัญหาของการพึ่งพาแหล่งข้อมูลฟรีคือการตรวจสอบว่ามีการปรับปรุงราคาปิดหรือไม่และการปรับปรุงเหล่านั้นได้ดำเนินการอย่างไร
สร้าง DataFrame ราคาปิดสิบอันดับแรกของ S&P500
การเข้าถึงข้อมูลของหุ้นเดียวเป็นเรื่องที่ดี แต่เราจะเข้าถึงข้อมูลของหุ้นหลายตัวและวิเคราะห์ทั้งหมดในที่เดียวได้อย่างไร? โครงสร้างของการดาวน์โหลดจาก Stooq ทำให้การทำงานนี้ซับซ้อนมากขึ้น ในขณะที่คุณสามารถบอกได้โดยทั่วไปว่าหุ้นอยู่ในภูมิภาคหรือการแลกเปลี่ยนใด คุณไม่สามารถรับประกันได้ว่าหุ้นนั้นจะอยู่ในโฟลเดอร์ย่อยใด ในกรณีของ AAPL มันอยู่ภายใต้ us/nasdaq stocks/1/ แต่การใช้เวลาค้นหาสัญลักษณ์หุ้นในทุกๆ โฟลเดอร์ย่อยนั้นเป็นเรื่องที่ไม่คุ้มค่า โชคดีที่ Python 3.5+ มาพร้อมกับ glob ซึ่งเป็นการขยายรูปแบบเส้นทางแบบ Unix Glob ช่วยให้เราสามารถค้นหาไฟล์เฉพาะในไดเรกทอรีย่อยบนเส้นทางที่กำหนดได้แบบวนซ้ำ
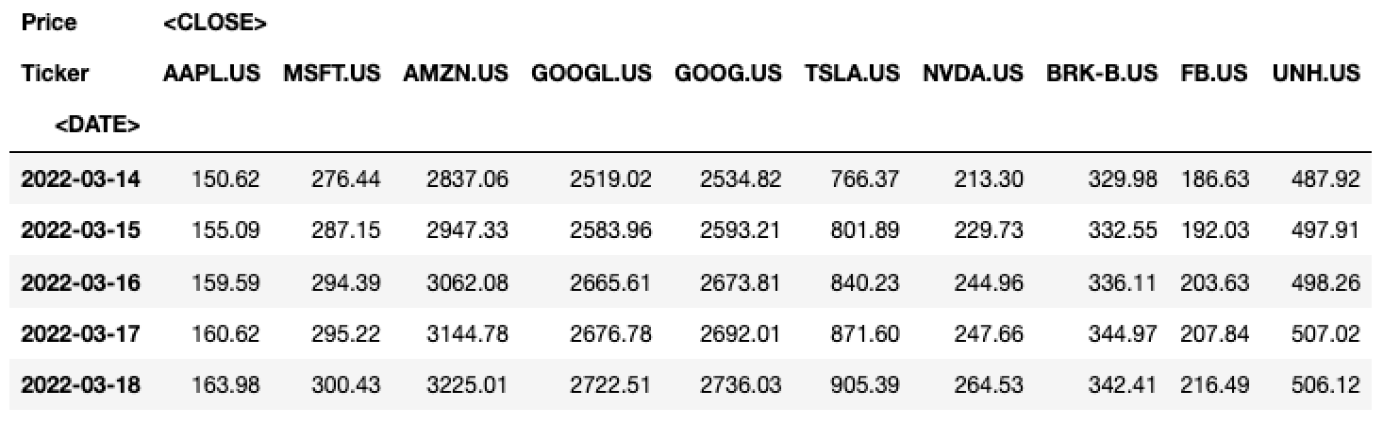
เพื่อแสดงให้เห็น เราจะสร้าง DataFrame ของราคาปิดสำหรับสิบบริษัทชั้นนำใน S&P500 เราจะสร้างพจนานุกรมของ DataFrame โดยที่คีย์เป็นสัญลักษณ์และค่าคือ DataFrame ที่มีข้อมูล OHLCV ประวัติศาสตร์ เราจะสร้าง MultiIndex สำหรับแต่ละ DataFrame โดยใช้วันที่และสัญลักษณ์เป็นระดับ สิ่งนี้จะช่วยให้เราสามารถเชื่อมต่อพวกมันเข้าด้วยกันและแยกออกเพื่อสร้าง DataFrame สุดท้ายที่แถวจะถูกจัดทำดัชนีโดยวันที่และคอลัมน์จะถูกจัดทำดัชนีโดยสัญลักษณ์ที่เลือก มาเริ่มกันเถอะ
เราจะใช้ไลบรารีสามตัวคือ Glob, OS และ Pandas OS และ Glob เป็นส่วนหนึ่งของไลบรารีมาตรฐานของ Python 3 ดังนั้นเราจะเพิ่มการนำเข้าไว้เหนือการนำเข้าของ Pandas และเว้นบรรทัดระหว่างทั้งสอง สิ่งนี้ช่วยแยกความแตกต่างระหว่างการนำเข้ามาตรฐานและการนำเข้าจากบุคคลที่สาม และเป็นแนวปฏิบัติที่ดีที่สุด
import glob import os import pandas as pd
ตอนนี้เรามีการนำเข้าของเราแล้ว เราจะกำหนดชื่อสัญลักษณ์ของหุ้นสิบอันดับแรกใน S&P500 ในทางปฏิบัติ นี่อาจเป็นการจัดกลุ่มหุ้นใด ๆ ที่คุณต้องการ ตราบใดที่หุ้นทั้งหมดอยู่ในภูมิภาคสหรัฐอเมริกาในไฟล์ดาวน์โหลดของ Stooq เราจะสร้างทูเพิลที่มีสัญลักษณ์หุ้นของเรา เหตุผลสำหรับเรื่องนี้คือเราวางแผนที่จะสร้างพจนานุกรมของ DataFrames ทูเพิลเป็นแบบไม่เปลี่ยนแปลง ดังนั้นจึงมั่นใจได้ว่าลำดับของตัวย่อหุ้นจะไม่เปลี่ยนแปลง แม้ว่าจะเป็นความจริงที่ Python 3.7 มีการจัดเตรียมพจนานุกรมที่รักษาลำดับของข้อมูล แต่พฤติกรรมนี้ยังไม่ได้รับการบันทึกไว้ในเอกสารและอาจไม่สามารถรับประกันได้ พจนานุกรมคือการจับคู่คู่กุญแจและค่า ดังนั้นจึงไม่มีลำดับ การใช้ทูเพิลจะทำให้เรารักษาลำดับของตัวย่อในพจนานุกรมได้
# Top 10 S&P 500 tickers
sp_10 = ('AAPL.US', 'MSFT.US', 'AMZN.US', 'GOOGL.US', 'GOOG.US', 'TSLA.US', 'NVDA.US', 'BRK-B.US', 'FB.US', 'UNH.US')ถัดไปเราสร้าง list comprehension โดยเราจะวนลูปผ่านแต่ละ ticker ใน tuple ของเราและเรียก glob.glob() พร้อมกับ os.path.join() สิ่งนี้สร้างรายการของสตริงที่แสดงตำแหน่งไดเรกทอรีของไฟล์ข้อมูลแต่ละไฟล์ สุดท้าย เมื่อ glob คืนค่ารายการ เราจะได้รายการของรายการ ซึ่งแต่ละรายการย่อยมีสตริงเดียวในนั้น เราทำให้รายการของรายการแบนลงเป็นรายการเดียวของสตริงเพื่อที่เราจะได้สร้างพจนานุกรมของ DataFrames ของเรา
# Use glob to find the data files for the tickers path = "/path/to/your/Downloads/data/daily/us/**/" ohlcv_data = [glob.glob(os.path.join(path, ticker + ".txt"), recursive=True) for ticker in sp_10] # flatten glob list of lists flat_ohlcv = [item for sublist in ohlcv_data for item in sublist]
ตอนนี้ที่เราได้ที่อยู่ทั้งหมดสำหรับไฟล์แล้ว เราสามารถส่งไปยัง Pandas read_csv() ได้เหมือนที่เราทำก่อนหน้านี้ ครั้งนี้เราจะใช้พารามิเตอร์คีย์เวิร์ด index_col เพื่อกำหนดให้คอลัมน์วันที่เป็นดัชนีของเรา เราจะเรียกใช้ฟังก์ชันภายใน dictionary comprehension และทำการ enumerate ผ่าน tickers ใน top ten S&P constituent tuple ของเราเพื่อให้ได้คีย์สำหรับ dictionary ค่าจะเป็น DataFrames
# Create a dictionary of dataframes with index as date
stooq_data = {name: pd.read_csv(flat_ohlcv[i], index_col="") for i, name in enumerate(sp_10s)}ตอนนี้เรามี DataFrames ของเราแล้ว เราสามารถสร้าง MultiIndex ด้วยวัตถุ datetime และ ticker เป็นแต่ละระดับได้ สิ่งนี้จะช่วยให้เราสามารถเชื่อมต่อ DataFrame ทั้งหมดและแยกข้อมูลออกมา สร้าง DataFrame สุดท้ายที่มีวันที่และราคาปิดสำหรับสิบบริษัทชั้นนำในดัชนี S&P500 เพื่อให้บรรลุเป้าหมายนี้ เราจะลบคอลัมน์ที่ไม่ต้องการ แปลงวันที่จากจำนวนเต็มเป็นวัตถุวันที่และตั้งค่าคอลัมน์ MultiIndex
for k in stooq_data.keys(): # change date format stooq_data[k].index = pd.to_datetime(stooq_data[k].index.astype(str), format="%Y-%m-%d") # set MultiIndex stooq_data[k].set_index([stooq_data[k].index, ""], inplace=True) # drop all columns except close stooq_data[k].drop(["", "", "", "", "", "", ""], axis=1, inplace=True)
ตอนนี้เราสามารถเชื่อมต่อ DataFrames ของเราได้โดยใช้วิธี .items() โดยมั่นใจว่าเราไม่จัดเรียงเพื่อรักษาลำดับของเราและเราใช้คีย์เวิร์ด join="outer" พฤติกรรมทั้งสองนี้ถูกระบุเป็นพารามิเตอร์เริ่มต้นสำหรับคำสำคัญ แต่เราได้ระบุไว้ที่นี่เพื่อป้องกันไม่ให้โค้ดของเราเสื่อมสภาพในอนาคต
result = pd.concat([v for k, v in stooq_data.items()], join="outer", sort=False)
สุดท้ายเราก็ทำการ unstack Dataframe แบบ MultiIndex ของเราเพื่อสร้างคอลัมน์สำหรับราคาปิดของ ticker ทั้งหมด ตามพฤติกรรมเริ่มต้น unstack() จะจัดเรียงข้อมูลตามลำดับตัวอักษรของป้ายกำกับ ซึ่งหมายความว่าสิบอันดับแรกของเราจะไม่อยู่ในลำดับตามมูลค่าตลาดอีกต่อไป ในการจัดเรียงคอลัมน์ใหม่ เราสามารถสร้าง MultiIndex จากทูเพิล S&P top ten ดั้งเดิมของเราได้
final_df = result.unstack()
mindex_tup = [("", ticker) for ticker in sp_10]
mindex_cols = pd.MultiIndex.from_tuples(mindex_tup, names=['Price', 'Ticker'])
stooq_sp10_close = pd.DataFrame(final_df, columns=mindex_cols)การใช้คำสั่ง Pandas pd.DataFrame.tail() ข้อมูล DataFrame สุดท้ายของเรามีลักษณะดังนี้
การใช้ไลบรารีเพื่อดึงข้อมูลจาก Stooq
ไลบรารี Python Pandas-DataReader ช่วยให้คุณเข้าถึงข้อมูล Stooq ได้ แม้ว่าวิธีนี้จะง่ายกว่าวิธีที่กล่าวถึงข้างต้นมาก แต่ในขณะเขียนบทความนี้สามารถเข้าถึงข้อมูลประวัติศาสตร์ได้เพียงห้าปีผ่านห้องสมุด Data-Reader เท่านั้น มาดูตัวอย่างกันเถอะ
import pandas_datareader.data as web
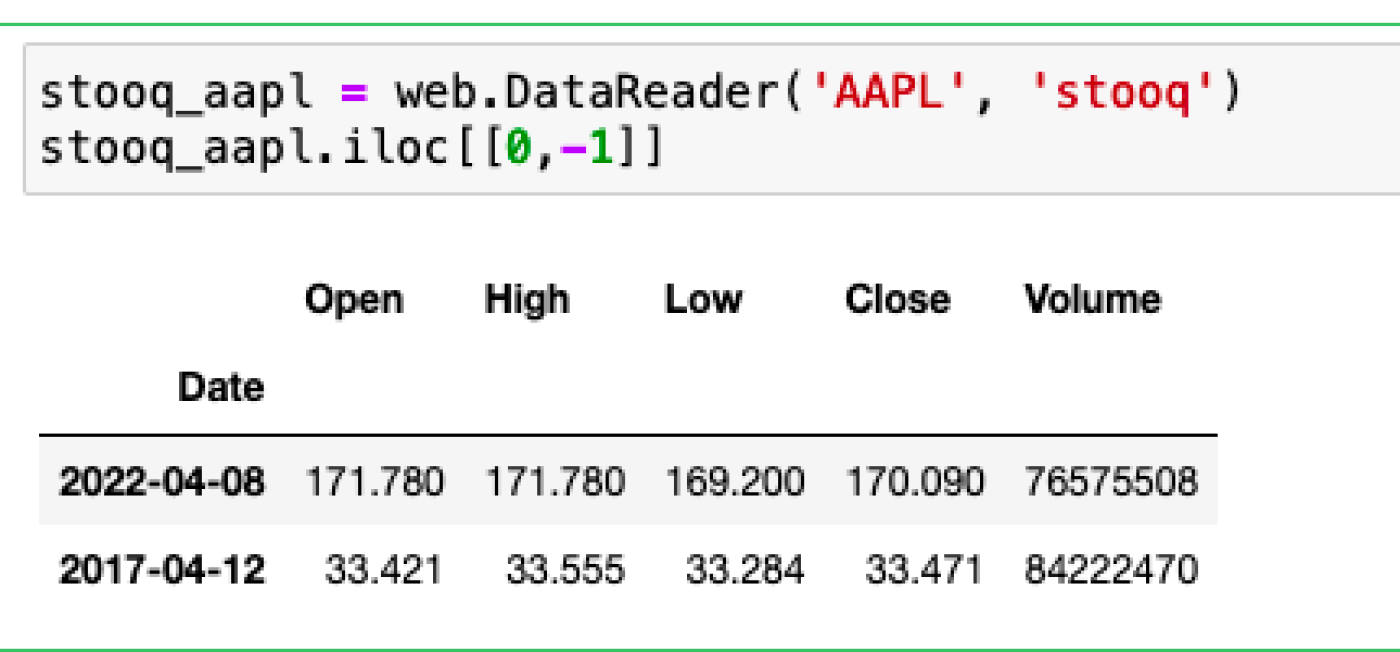
stooq_aapl = web.DataReader('AAPL', 'stooq')
stooq_aapl.iloc[[0,-1]]ที่นี่เรานำเข้าไลบรารี Data-Reader ตามที่เราได้ทำในบทช่วยสอนก่อนหน้านี้ สร้าง DataFrame สำหรับข้อมูล AAPL และจากนั้นใช้คำสั่ง Pandas df.iloc[] เพื่อดูแถวแรกและแถวสุดท้าย ดังที่คุณเห็น วันที่แรกที่มีอยู่คือเดือนเมษายน 2017 ซึ่งห้าปีก่อนจากเวลาที่เขียน
ข้อมูลปัจจุบันของ Stooq
Stooq ยังให้บริการภาพตัดขวางในช่วงเวลาหนึ่งของฐานข้อมูลของพวกเขา สิ่งนี้มีรูปแบบเป็นการดาวน์โหลด CSV สำหรับข้อมูลรายวันที่มีหลักทรัพย์ทั่วโลก ดัชนี และสกุลเงินมากกว่า 12,000 รายการ สำหรับข้อมูลรายชั่วโมงและทุก 5 นาที พวกเขามีข้อมูลราคาให้สำหรับคู่สกุลเงิน 66 คู่และดัชนี 56 ดัชนี ในการเข้าถึงข้อมูลปัจจุบันหรือข้อมูลสำหรับวันที่เฉพาะ คุณเลือกวันที่และจากนั้นระบุการรวมกันที่แตกต่างกันของข้อมูลรายวัน รายชั่วโมง หรือข้อมูลทุก 5 นาที
สรุป
ในบทความนี้เราได้แนะนำผู้ให้บริการข้อมูลตลาดประวัติศาสตร์ Stooq เราได้ดูข้อมูลที่มีอยู่ วิธีการดาวน์โหลดและปรับรูปแบบให้เหมาะสมกับความต้องการของเรา มีข้อมูลที่หลากหลายให้ดาวน์โหลดในความถี่เวลาที่แตกต่างกัน อย่างไรก็ตาม ไม่มี API และไฟล์ข้อมูลเมื่อถูกแตกไฟล์แล้วจะใช้พื้นที่มาก ราคาปิดที่ให้มานั้นได้รับการปรับแล้ว และเท่าที่เราทราบ ไม่มีข้อมูลที่ไม่ได้รับการปรับแยกต่างหาก นอกจากนี้ยังมีความแตกต่างในชื่อสัญลักษณ์หุ้นเมื่อเปรียบเทียบกับมาตรฐานในอุตสาหกรรม หากคุณกำลังมองหาข้อมูลเพื่อทดลองใช้ Stooq มีประวัติข้อมูลที่หลากหลายซึ่งสามารถเข้าถึงและจัดการได้ตามความต้องการส่วนใหญ่ ในบทความถัดไปเราจะพิจารณาผู้จำหน่ายข้อมูล AlphaVantage และ Tiingo
อ้างอิง :An Introduction to Stooq Pricing Data
จาก https://www.quantstart.com/articles/an-introduction-to-stooq-pricing-data/
ร่วมเเสดงความคิดเห็น :
Recent post

2025-01-10 10:12:01

2024-06-10 03:19:31

2024-05-31 03:06:49

2024-05-28 03:09:25
Tagscloud
บทความอื่นๆที่น่าสนใจ
บทความที่น่าสนใจอื่นๆยังมีอีกมากลองเลืือกดูจากด้านล่างนี้ได้นะครับ

2023-09-06 11:19:12

2024-09-10 10:52:10

2024-09-17 11:24:11

2024-04-12 11:25:15

2024-09-10 01:27:37

2024-09-04 11:48:52

2024-03-27 04:49:48

2024-02-19 05:37:43

2023-09-19 03:43:27